The Curse Of The Name-Value Pair
OK, I admit it - I've been listening to Alan Hansen far too much recently, but I can't resist saying it: it was a shocker. No, I'm not referring to Euro 2008, but a database design that I looked at some years ago. All the bank wanted was a nice little settlement system; what they got was a shocker: a complete workflow system that just happened to be doing settlements.
It was horrendous: loads of worker processes, thousands of virtual objects flying around the system - being taken off queues, being processed, being put back onto other queues. Some of the tasks involved creating new virtual objects that were put on other queues, whilst others destroyed objects that had been created elsewhere. All of the queues and objects were stored in tables in the database, and all in all, to settle just one trade took over 10,000 SQL queries. Yes you read that correctly.
It didn't need Sherlock Holmes to work out why they had a performance problem. But ironically, they weren't too concerned about any of that - they were more bothered about the huge number of deadlocks they were getting. The funny part about it is, I even guessed who'd designed it. Talk about ambulance chasing. Some years earlier the same software house had produced a database design as part of the replacement for a legacy system, and they'd obviously taken the whole entity / relationship thing a little too literally, because at the heart of their design were tables called "Entity" and "Relationship".
Anyway, the point of this article is about the way the virtual objects were stored on the database. There were many different types of object, each having varying numbers of attributes, and these were all stored in the database as name-value pairs. For those of you who don't know what name-value pairs are, then let me explain.
Name-Value Pairs
Imagine that our virtual object is a cat. Every cat has a number of different properties: name, colour, owner etc., and each of these is going to be stored in a separate row in the Attribute table. The name-value pair refers to the fact that our Attribute table has two important columns: one holding the name of the attribute, and the other it's value. So one of the rows might have the attribute name "Colour", and a corresponding value of "Black".
Figure 1: The attributes of a cat stored in a table as name-value pairs
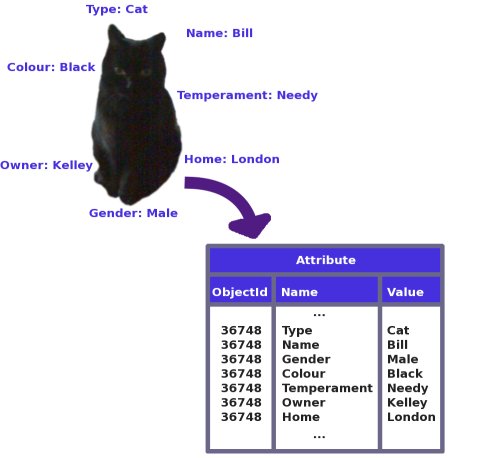
Unfortunately for Bill here, despite protestations of "I am not a number, I am a cat", we have to give him a serial number, or Object Id. This is to differentiate him from other objects, and to link his attributes together.
Now I generally don't like giving "always try to" advice, since techniques don't work in every situation, but I'm going to stick my neck out on this one and say this: avoid using name-value pairs like the plague. From a performance point of view, they are a nightmare:
- Instead of a single insert, update, or delete per object, there is one for each attribute: creating a virtual object with 10 attributes involves inserting 10 rows; changing 10 attributes involves updating 10 rows; and of course destroying an object with 10 attributes involves deleting 10 rows. In fact, this was one of the reasons that the system mentioned at the beginning had so many problems with deadlocks: there were quite often thousands of SQL queries all within the same transaction.
- There is a certain amount of data duplication: not only is the object id duplicated for every attribute, but the "name" part of the name-value pair (i.e. the attribute name) also takes up space.
- The "value" part of the name-value pair (i.e. the attribute value) has to be the same data type, which will undoubtedly be a variable length character string (unless you do something really strange, and have a different table for each type). If you're storing integers or dates, these have to be stored as strings, and must therefore be converted every time they are moved in or out of the database.
So how should you do it? Well the easiest and most obvious thing to do is to just have a table for each different type (or class) of object, with each column storing a single attribute of the correct datatype. Nice and simple: any creation, modification, or destruction of an object requires just a single inserted, updated, or deleted row.
Figure 2: The attributes of a cat stored in a table as a single row
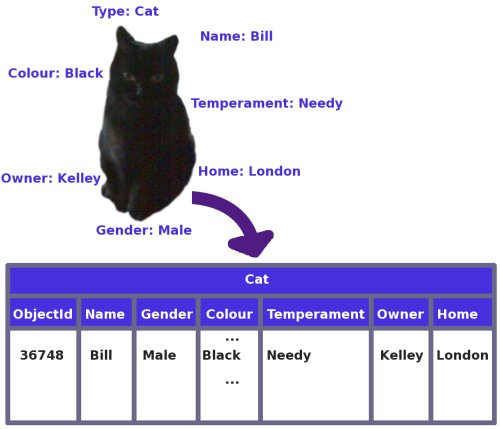
At the risk of providing you with an excuse not to take my advice, it wouldn't be a particularly balanced article if I didn't mention some of the reasons why people do use name-value pairs:
- If there are lots of different classes of objects, having a table for each one can become unmanageable: 100 different object types = 100 different tables.
- If an object has a large number of possible attributes, but only a small number of them are usually populated at any time, name-value pairs can drastically reduce the amount of space used.
- Using name-value pairs minimises the amount of maintenance that needs to be done on the database, since object class changes can be made without the need for corresponding database schema changes: it is easy to add new classes or attributes, for example.
- Most database systems have limits on the number of columns in a table, or the size of a row. Obviously if the virtual object has too many attributes or is simply too big, and exceeds these limits, then the table-per-class approach is impossible.
Although this looks like I'm giving you permission to use name-value pairs, the advice still stands: do not use name-value pairs. In the rest of this article I'm going to present a couple of ways of doing just that, but just to show how nice I am, I also provide some techniques for improving performance if you're going to take no notice of me, and use them regardless.
Serialisation
One way of avoiding name-value pairs is to use a technique called serialisation. Those of you who are familiar with Java programming may already be aware of this, as the language provides a framework for serialising Java objects. As with Java serialisation, it involves encoding an object into a string of bytes, and then storing them as raw data in a table, as a variable-length binary column. Of course, you can use serialisation even if Java is not your development language.
Figure 3: Serialising / de-serialising an object to / from a table
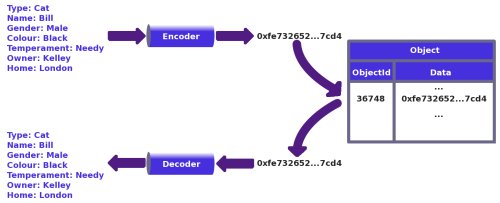
The exact method of encoding is left up to the architect or designer: it may be as simple as GZIPping a string representation of the object, or as complex as creating a custom compression scheme. Ideally it would allow even a fully populated object to be stored in a single row. Note that I'm not necessarily advocating storing the encoded object as a binary large object (BLOB), unless your particular database management system stores these in the row itself rather than in a separate page chain, and allows the column to be retrieved using standard SQL syntax. Sybase, for example, uses a separate page chain for "image" columns (its equivalent of a BLOB), and uses a different method to read and write data.
Serialisation isn't for everyone, and there are a number of implications of using it:
- Unless you have chosen an encoding that uses fixed widths for the attributes, the object will need to be fully encoded and decoded everytime it is used. Updating single attributes using just SQL is no longer an option.
- The data can no longer be interpreted simply by looking at it (by administrators or developers). Running standard SQL queries on the table will simply show binary data.
- Indexing attributes is impossible unless your database management system supports function-based indexes, and you have a suitable function (or user-defined function) that can decode the serialised object. Having said that, you can always create additional columns for attributes that you want to index, and duplicate (or remove) them from the serialised (encoded) object.
I should probably mention XML at this point, since some database management systems provide a native datatype that allows XML to be stored directly in a table. This makes it possible to store an XML representation of a virtual object. Personally I'm always extremely cautious about using XML; from a performance point of view it's a bit of a double-edged sword:
- Some relational database management systems (RDBMSs) allow indexes to be created on the XML attributes and containers (DB2, for example). These can improve performance in some cases.
- Converting an object to XML and parsing it back again is quite an intensive operation, even with the fastest parsers. There is also the overhead of maintaining an XML schema.
- XML is pretty inefficient size-wise, and so an XML representation of an object will take up much more space than an efficient serialisation algorithm.
As an architect or designer, you should be aware of it, and have it as a weapon in your performance 'arsenal', but you may want to consider carefully whether you actually want to use it. Do not just succumb to the XML hype - it's only another text format after all.
A final point is that some RDBMSs even let you store Java objects directly in the database, although it may be that yours actually uses Java serialisation to do this. Unfortunately Java serialisation is pretty slow, and may not be the most efficient in terms of size. Also, you probably won't be able to store and retrieve the object using standard SQL syntax.
Vertical Fragmentation
Another technique for dealing with large objects, or those with sparsely populated attributes, is that of vertical fragmentation - splitting attributes over more than one table. Another way of looking at it is that rather than one table per object, there is one main table plus one or more overflow tables.
To use this approach, you first need to collect some statistics on the usage of attributes in your object:
- If you are interested in performance, then the statistics need to be the number of times that the attributes are referenced, as a proportion of the number of times that any part of the object is referenced.
- If you are interested in minimising space, then the statistics need to be the proportion of time that the attributes are populated.
You then need to rank your attributes by the statistics that you have collected. You will end up with a table that looks like this:
| Attribute Name | Usage |
|---|---|
| Attribute1 | 98% |
| Attribute2 | 98% |
| Attribute3 | 96% |
| Attribute4 | 80% |
| ... | |
| Attribute35 | 7% |
| ... | |
| AttributeN | 2% |
Then you need to draw one or more lines on the table. Where you draw the lines is a matter for your judgement, specific requirements at your site, limitations of your RDBMS, and hopefully some testing. You may decide, for instance, that the top ten most commonly used attributes will be in the main table, while the rest will go into a single overflow table. If you are concerned about both performance and space, then you may want to juggle the attributes around between the main and overflow tables accordingly.
Remember that each additional overflow table will carry a performance penalty due to an extra join, so the fewer the better, but the advantages of this approach are:
- Creating or destroying objects involves one insert or delete per table rather than per attribute.
- Modifying attributes involves one update for every table that holds a value that is being changed.
- Retrieving objects involves a single select from the main table, with outer joins to the overflow tables.
- We are using the relational database properly: indexing any attribute is easy, set-based operations are possible, and data retrieved from tables can be read on screen without any decoding.
- Where different object classes have common attributes (e.g. in the case of inheritance), overflow tables may be shared between them.
Hybrid Approach
Naturally, the two techniques suggested above are not mutually exclusive. It is perfectly possible to mix and match them both according to your specific requirements: you may, for example, have overflow tables that store serialised attributes.
If You Must
OK, so you've completely ignored everything I've just said, and you're going to use name-value pairs anyway. Alternatively, you're using a content management system, and are stuck with them. I'll give you the benefit of the doubt, and assume that now you know how bad they are, you're going to change your database design, but for the moment you need an interim solution to aleviate your slow performance. Here I look at some techniques for improving the performance of name-value pair operations.
From here on in, the examples are given for Sybase Adaptive Server Enterprise (ASE), but it should be possible to replicate the techniques on other database management systems.
Adding Attributes
If you are creating new virtual objects or adding attributes to an existing object, instead of inserting attributes separately like this:
INSERT INTO Attribute ( ObjectId, Name, Value ) VALUES ( 36748, "Attribute1", "Value1" ) INSERT INTO Attribute ( ObjectId, Name, Value ) VALUES ( 36748, "Attribute2", "Value2" ) INSERT INTO Attribute ( ObjectId, Name, Value ) VALUES ( 36748, "Attribute3", "Value3" ) INSERT INTO Attribute ( ObjectId, Name, Value ) VALUES ( 36748, "Attribute4", "Value4" ) INSERT INTO Attribute ( ObjectId, Name, Value ) VALUES ( 36748, "Attribute5", "Value5" )
You can do them in a single query:
INSERT INTO Attribute ( ObjectId, Name, Value ) SELECT 36748, "Attribute1", "Value1" UNION ALL SELECT 36748, "Attribute2", "Value2" UNION ALL SELECT 36748, "Attribute3", "Value3" UNION ALL SELECT 36748, "Attribute4", "Value4" UNION ALL SELECT 36748, "Attribute5", "Value5"
Notes:
- Sybase has a limit of 256 items when using the UNION ALL clause, so more than 256 attributes and you'll need to have multiple INSERT statements.
- The entire query is sent to the database server in one string - reducing both the network and parsing overhead.
- The entire query is a single transaction, compared to multiple transactions (obviously if you are in CHAINED mode then the first query will be a single transaction as well).
Updating Attributes
Instead of updating attributes separately like this:
UPDATE Attribute SET Value = "Value1" WHERE ObjectId = 36748 AND Name = "Attribute1" UPDATE Attribute SET Value = "Value2" WHERE ObjectId = 36748 AND Name = "Attribute2" UPDATE Attribute SET Value = "Value3" WHERE ObjectId = 36748 AND Name = "Attribute3" UPDATE Attribute SET Value = "Value4" WHERE ObjectId = 36748 AND Name = "Attribute4" UPDATE Attribute SET Value = "Value5" WHERE ObjectId = 36748 AND Name = "Attribute5"
You can update multiple attributes in one query (and again, one transaction):
UPDATE Attribute SET Value = CASE Name WHEN "Attribute1" THEN "Value1" WHEN "Attribute2" THEN "Value2" WHEN "Attribute3" THEN "Value3" WHEN "Attribute4" THEN "Value4" WHEN "Attribute5" THEN "Value5" ELSE Value -- Not strictly required END WHERE ObjectId = 36748 AND Name IN ( "Attribute1", "Attribute2", "Attribute3", "Attribute4", "Attribute5" )
Retrieving Attributes
Obviously if you are only returning attributes to a client, and it doesn't matter that they are retrieved as a result set with multiple rows, then you can use a simple SELECT query. However, there may be times when you want to (e.g.) retrieve attribute values into variables in a stored procedure. A really sneaky way of doing this is as follows:
DECLARE @value1 varchar(50), -- Or whatever your Value column is defined as @value2 varchar(50), @value3 varchar(50), @value4 varchar(50), @value5 varchar(50) UPDATE Attribute SET @value1 = CASE Name WHEN "Attribute1" THEN Value ELSE @value1 END, @value2 = CASE Name WHEN "Attribute2" THEN Value ELSE @value2 END, @value3 = CASE Name WHEN "Attribute3" THEN Value ELSE @value3 END, @value4 = CASE Name WHEN "Attribute4" THEN Value ELSE @value4 END, @value5 = CASE Name WHEN "Attribute5" THEN Value ELSE @value5 END WHERE ObjectId = 36748 AND Name IN ( "Attribute1", "Attribute2", "Attribute3", "Attribute4", "Attribute5" ) SELECT @value1, @value2, @value3, @value4, @value5
It's sneaky because even though we've said we're going to update the Attribute table, we are only actually updating the variables @value1 - @value5. The variables are updated as we go along, which is what makes it very useful. Ideally we would like to use a SELECT to do the same thing, because the downside of using an UPDATE is that records are written to the transaction log. Unfortunately you can't use a SELECT in Sybase here because the variables are not updated as we go along (i.e. after each row has been scanned) - any reference to the variables will yield the values that they had before the query started.
If you don't mind the log writes, then this is also a useful technique for concatenating values into a single string:
DECLARE @string varchar(50) -- Or big enough to hold the final string SELECT @string = "" UPDATE Attribute SET @string = @string + Value + ";" WHERE ObjectId = 36748 AND Name IN ( "Attribute1", "Attribute2", "Attribute3", "Attribute4", "Attribute5" ) SELECT @string -------------------------------------------------- Value1;Value2;Value3;Value4;Value5;
As always, you should test the queries to determine how they perform on your database system.